
・外国の休日や時差を意識すること。
特に、アメリカは時差的に一番遅れているので、その日に日本で起きたことを反映して売買を行うようです。
・日本の休日中にも外国市場は動いていることを意識すること。
世界情勢で何かあっても、日本が休みで売買が出来ないことを意識する。
・お金持ちは三カ月ごとに決算している。
1月から三カ月周期。決算の直後は買い、決算の直前は売り。
その時は株価が大きく動くらしい。
そのリズムに合わせて売り買いするとよい。
・国会の開催時期、国際会議で何が決まったか意識する。・日本に緊張が走ると、アメリカやヨーロッパにお金が集まる。
北朝鮮のミサイルなど。
・ある株が値上がりして、その日に関連が分が値下がってなければ、関連株が上がってなければ、明日上がる可能性あり。
ただし、日経平均株価が一緒に下がってるのにその株だけ上がってたら、無視する。
・定期的にニュースやネットをチェックする。
ブルームバーグやyahooファイナンスをチェック。
テレビの経済ニュースや、テレ東の23時のワールドサテライトを観る。
・大衆週刊誌の株特集に注目。
多くの人が読む週刊現代や週刊ポストなどに株特集があったり、タブロイドの記事なんかもチェック。
沢山の人が見ているから、それだけ影響力があり、株価を動かす可能性があるから。
・株価は天気にも左右される
夏は暑いから飲料業界やアイス業界の株が上がるとか。
・株日記を定期的に書く
・今週、どんな大きな出来事があったか
・マーケットではどんな出来事があったか、株価は総じて上がったか
・今週どんな銘柄で儲けたか、損したか。その理由。
・飲み会や世間話で得た情報は何か。
・相場予想図を描く
・出来高から観て、これから盛んに売買されそうだなと思う銘柄一つ。
・先週一週間で耳に残ったニュース三つ。
・余裕がありそうな曜日。
|
2017年11月19日日曜日
【株】儲かるためのポイント
2017年9月17日日曜日
西村賢太の私小説のおススメ
西村賢太の私小説をよく読みます。
発表されてる作品が、1作品を除き私小説という作家です。
芥川賞を獲ってます。
ちょうど風俗に行こうとしたとき、受賞の電話を貰ったという逸話があります。
藤沢清造という作家に、異常なほど傾倒していて、本人に許可なく(死んでるから許可取れないけど。)没後弟子ということを自分で決めてしまっています。
能登の七尾のにある清造の菩提寺にある墓を譲り受けたり。
清造の墓の横に自分の墓を建てたり。
ちょっと執着がすごいですが、こんなに好きなものがあるって、とても羨ましいです。
清造にはまったきっかけが、自分の惨めな人生と、清造がいろいろと被るからというものらしいです。
芥川賞を獲り、女性にもてるようになった、今の西村先生は、もう惨めではないと思います。
その小説ですが、大きく分けて、以下のような傾向があります。
・若いころの惨めなエピソード
・秋恵もの
・清造がらみ
・芥川賞受賞後の最近のこと
私は、若いころの惨めだったころのエピソードを楽しく読んでます。
次に清造がらみの話。
秋恵ものは、ちょっとマンネリがあり、好きな話とそうでない話がありますね。
最近の話は、ちょっと文章の密度が薄くなって、マイルドな感じです。
読んでる中からレビューを。
苦役列車 ★★★★★
インターネットもスマートフォンも、ガラケーすら登場しない80年代の頃のお話です。
主人公は一人暮らしですが、家に電話すら引いてません。
今の人から見ると、いったいどうやって連絡とってるんだろう?って感じですね。
戦後直後とか、戦前でもないのに、中学しか出ていません。
高校に行かなかった特別な理由や、別にやりたいことがあったとかそういう描写はありません。
ちょっと想像できないですね。
当然、仕事といえば日雇いくらいしかないので、そこで働いている日常の場面から、お話がスタートします。
日雇いの仕事に通う主人公の日常が描かれています。
大事件が起こることもないです。
久々にできた職場での友人との付き合い、その友人とのちょっとしたすれ違いから生じる負の感情や、その友人の
彼女が不細工だったのを見て優越感に浸るところ。など、時代や生活環境は違うけど、誰にでもちょっと当てはまる
感情が描写されていると思います。
文体がもっさりというか、殊更詳細な部分もあったりで、色んなところが昭和っぽく古臭い感じがします。
読んでると、舞台が80年代なのかどうかも一瞬怪しくなるのですが、友人に、スタローンの「コブラ」という映画を観に行こうと
誘っている場面があるので、なんとか戻ってくることができました。
でも、全然とっつきにくいわけじゃなく、むしろその古臭さがたまらなくいいです。
主人公は昭和の文学青年みたいに古臭い話し方なのですが、友人やその他の人は現代の話し方をしていて、会話は成立して
いるのだけど、読んでると違和感があったりします。
まるで、主人公だけ、石ころ帽子をかぶらされて、ぽつんとしてる感じです。
それが、何だか微笑ましいというか、純真な感じもします。
無銭横町 ★★★★

風俗嬢に金をだまし取られたり、秋恵の頭をスリッパではたいてた時期に比べると、
だいぶ軽くなったなという感じです。
ハイライトがマイルドセブンになった感じです。
本のタイトルになってる無銭横丁だけは、昔の感じが戻った風でした。
初期のころの密度が濃くて改行が少ない文章がまた読みたいです。
でも、軽くなった分、読みやすくなった部分もあります。
主人公が、兎に角ネガティブで、田中英光に関することだけ前向きなので、アンバランスな人物になってます。
でも、人生でこれだけ楽しめるものを見つけることが出来たことは、幸せなことだし、うらやましくもあります。
この本では登場しないけど、のちに藤澤清造の本に出会い、小説家を目指すきっかけを得るのだから、どんな
楽しみもばかにできません。
形影相弔・歪んだ忌日 ★★★★

難しい漢字やら、言い回しやらに独特な感じはありますが、この文体が好きな人は一定数いて、はまってる人もいると思います。
昭和の文学青年みたいな古臭いセリフを吐く主人公に対して、同棲している女が、そのことを気にせず今風の口調で話しています。
主人公と女との、言い合いの喧嘩のときなど、その落差のせいで、主人公が時代錯誤な昭和初期の文学の人みたいなキャラクターっぽく見えてきて、
非常に滑稽で可笑しい。
時代に取り残された人みたいになっている。
確信犯で、そういうキャラ設定にしているのかどうかは分からないが、結果的に面白いのだから、成功していると思います。
短編6編が収録されています。
芥川賞受賞後の身辺の変化について書かれた話が印象的でした。
受賞後、音信不通の母親から突然手紙が届いて嫌な気分になった話や、自身が有名になったことで、清造忌に多数のマスコミや
文学かぶれがやってきてやりにくなったといった話。
受賞前やヤングの頃とは違う、別の感情、悩みが生まれてきたという感じです。
新しいステージに進んだのだろうと思いました。
棺に跨がる ★★★★

4編全て、同棲してた女性との痴話です。
描き割りなんて、全部似たような感じです。
女との冷え切った感情が、どうすればまた温もりを取り戻すのか、
自らの過ちを後悔しつつも、何をやっても振り向いてくれない女にプライドを気付つけられ、イラつきながらも、
彼女の機嫌を取る貫太の姿が、男の性をよく現してる。
男は、女に対して、未練たらたらに書かれてますが、身につまされる部分もあります。
だから、似たような話でも、とても面白いです。
短編4つですが、続き物のようです。
1,2,3と話が進むたびに、状況が悪化していきます。
蠕動で渉れ、汚泥の川を ★★★★
気になった方は、
やっぱり、芥川賞を獲った苦役列車から入るのがいいでしょう。
映画にもなったし。
|
プロントのケーキセットで食べて来た甘いものたち
ストレス溜まると甘いものが欲しくなる!
確かに。
そんな時は、プロントでケーキセットして甘いもの摂取してるなあ。
摂りすぎ注意!
中性脂肪の元だかんね!
ケーキセットは飲み物と甘いものをセットにして、別々に頼むより安くなる。
・ブルーベリースコーン

温めてもらえます。
ブルーベリーの酸っぱい感じとプレーンなビスケットみたいなスコーンのサクサクがいいですね。
・チーズケーキ

しっとりサクサクのビスケットみたいな下のシートがいいです。
ナッツが入っていて歯触りがいいです。
チーズケーキは甘くて濃厚なのでコーヒーと合います。
・チーズパンケーキのスフレ

これ最近出たみたいですね。
早速頼んでみました。
出来上がるまで時間が掛かるので、カウンターでは渡されず、席に着いて待っていると持って来てくれます。
メープルシロップとバター付き。
ホークとナイフでさっくりしっとり切れます。
口に入れてもしっとりでホンノリとチーズ味です。
ホットケーキを濃い目のチーズケーキと合わせた感じかな。
・チョコドーナツ

シュガーな歯触りの甘いドーナツ。
てかてかのチョコレートが印象的。
本当に甘いので、甘いものが本当に欲しいときにどうぞ。
・ブリュレinバウム

これ、人気あるんじゃないかな。
分厚いバームクーヘンの間にカスタードクリームが挟まってます。
で、こんがり焦げ目があるほど焼いているのでまさにブリュレな感じです。
ブリュレとバームクーヘンの合わせ技みたいです。
冷たく冷やしてあるので、クリームと生地がよりしっとりしていて美味しいでした。
疲れて甘いもの欲しいときは、ここに逃げ込もう。
|
2017年9月2日土曜日
【windowsのバッチコマンド】ファイルにある文字列をファイルを開かずに置換する方法
例えば、あるファイル「test.txt 」のなかにある「YYY.YYY.YYY.YYY」という文字列を「XXX.XXX.XXX.XXX」に変更したい場合、こういうバッチを作る。
このバッチをhenkan.batとします。
henkan.bat
ーーーーーーーーーーーーーーーーーーーーーーーーーーーーーーーーーー
@echo off
move test.txt test.txt.old
set infile=test.txt.old
set outfile=test.txt
set before1=YYY.YYY.YYY.YYY
set after1=XXX.XXX.XXX.XXX
type nul >%outfile%
setlocal enabledelayedexpansion
for /f "delims=" %%A in (%infile%) do (
set line=%%A
set line=!line:%before1%=%after1%!
echo !line!>>%outfile%
)
endlocal
del test.txt.old
ーーーーーーーーーーーーーーーーーーーーーーーーーーーーーーーーーー
test.txt(返還前)
ーーーーーーーーーーーーーーーーーーーーーーーーーーーーーーーーーー
YYY.YYY.YYY.YYY
aaaaaa
bbbbbb
YYY.YYY.YYY.YYY
xxxxxx
dddd
YYY.YYY.YYY.YYY
ーーーーーーーーーーーーーーーーーーーーーーーーーーーーーーーーーー
henkan.batを実行すると、test.txtはこうなります。
test.txt(返還後)
ーーーーーーーーーーーーーーーーーーーーーーーーーーーーーーーーーー
XXX.XXX.XXX.XXX
aaaaaa
bbbbbb
XXX.XXX.XXX.XXX
xxxxxx
dddd
XXX.XXX.XXX.XXX
ーーーーーーーーーーーーーーーーーーーーーーーーーーーーーーーーーー
「YYY.YYY.YYY.YYY」という文字列を「XXX.XXX.XXX.XXX」に変更されました。
他の文字列は変わらず。
1. 変換したい文字列が記載されているtest.txtをtest.txt.oldと名称変更します。
2. test.txt.oldを、1行ずつ読み込みます。
3. 読み込んだ1行に「YYY.YYY.YYY.YYY」という文字列があれば「XXX.XXX.XXX.XXX」に置換して、test.txtに出力します。
4. test.txt.oldの終わりまでループします。
元ファイルに空行がある場合は、変換後のファイルに空行が無くなってしまうので、そこは改善すべき点です。
置換したい文字列が複数あれば、その分変数を増やすなり配列で持たせればいいと思います。
★技術的な話
setlocal enabledelayedexpansionというのは、遅延環境変数を有効にするために記載しています。
for /f "delims="で、test.txtを1行ずつ読み込んでそれを、%%Aに入れています。
%%Aをline変数に入れ、
set line=!line:%before1%=%after1%!で、「YYY.YYY.YYY.YYY」という文字列を「XXX.XXX.XXX.XXX」に置換しています。
|
2017年8月20日日曜日
【ORACLEのお勉強#02】データポンプによる論理バックアップの使い道
ORACLEデータベースのバックアップと聞いて、多くの人が、まず思い浮かぶのがexp、impコマンドだと思います。
10gからは、その高機能版であるデータポンプが登場しました。
10gからは、その高機能版であるデータポンプが登場しました。
■普通のエクスポート、インポートとデータポンプの違い
・普通のエクスポート、インポート(exp、imp)
・10gまでサポートされている。11gからはサポートされていない。
・コマンド(例)
exp xxx/xxx file=a.dmp log=a.log tables=a
imp xxx/xxx file=a.dmp log=a_imp.log tables=a
・データポンプのようにディレクトリオブジェクトを用意したりといった下準備が要らない
・10gまでサポートされている。11gからはサポートされていない。
・コマンド(例)
exp xxx/xxx file=a.dmp log=a.log tables=a
imp xxx/xxx file=a.dmp log=a_imp.log tables=a
・データポンプのようにディレクトリオブジェクトを用意したりといった下準備が要らない
・データポンプ
・使うにあたり準備がいる
ディレクトリオブジェクトが必要
初期化パラメータSTREAMS_POOL_SIZEの設定が必要
・コマンド(例)
expdp xxx/xxx dumpfile=a.dmp logfile=a.log tables=a
impdp xxx/xxx dumpfile=a.dmp logfile=a_imp.log tables=a
・数千万クラスのテーブルだと、普通の普通のエクスポート、インポートよりデータ取得が速い
・使うにあたり準備がいる
ディレクトリオブジェクトが必要
初期化パラメータSTREAMS_POOL_SIZEの設定が必要
・コマンド(例)
expdp xxx/xxx dumpfile=a.dmp logfile=a.log tables=a
impdp xxx/xxx dumpfile=a.dmp logfile=a_imp.log tables=a
・数千万クラスのテーブルだと、普通の普通のエクスポート、インポートよりデータ取得が速い
普通のエクスポート、インポートよりもデータポンプの方が内部動作が複雑だし、設定をミスっているとORA-エラーが出て対処が必要になる場合もあります。
そのため、敷居が高い印象です。
私も使う前はそうでした。
10gの頃のデータポンプはバグが多かった......ですが、11gからは安定した動きになっています。
実際、普通のエクスポート、インポートとデータポンプの性能を比較すると、数百万件の単純な型しか持たないテーブルだと時間差を感じないのですが、LOBや構造体など複雑な型を持つテーブルを数千万件単位で取得する時は、データポンプの方が圧倒的に速かったです。
ここからは、データポンプに絞って書いていきます。
そのため、敷居が高い印象です。
私も使う前はそうでした。
10gの頃のデータポンプはバグが多かった......ですが、11gからは安定した動きになっています。
実際、普通のエクスポート、インポートとデータポンプの性能を比較すると、数百万件の単純な型しか持たないテーブルだと時間差を感じないのですが、LOBや構造体など複雑な型を持つテーブルを数千万件単位で取得する時は、データポンプの方が圧倒的に速かったです。
ここからは、データポンプに絞って書いていきます。
■よく論理バックアップ、物理バックアップと言われていますが......
データポンプで取得できるORACLEのデータは何でしょうか?
私は以下の図の範囲だと考えています。
私は以下の図の範囲だと考えています。
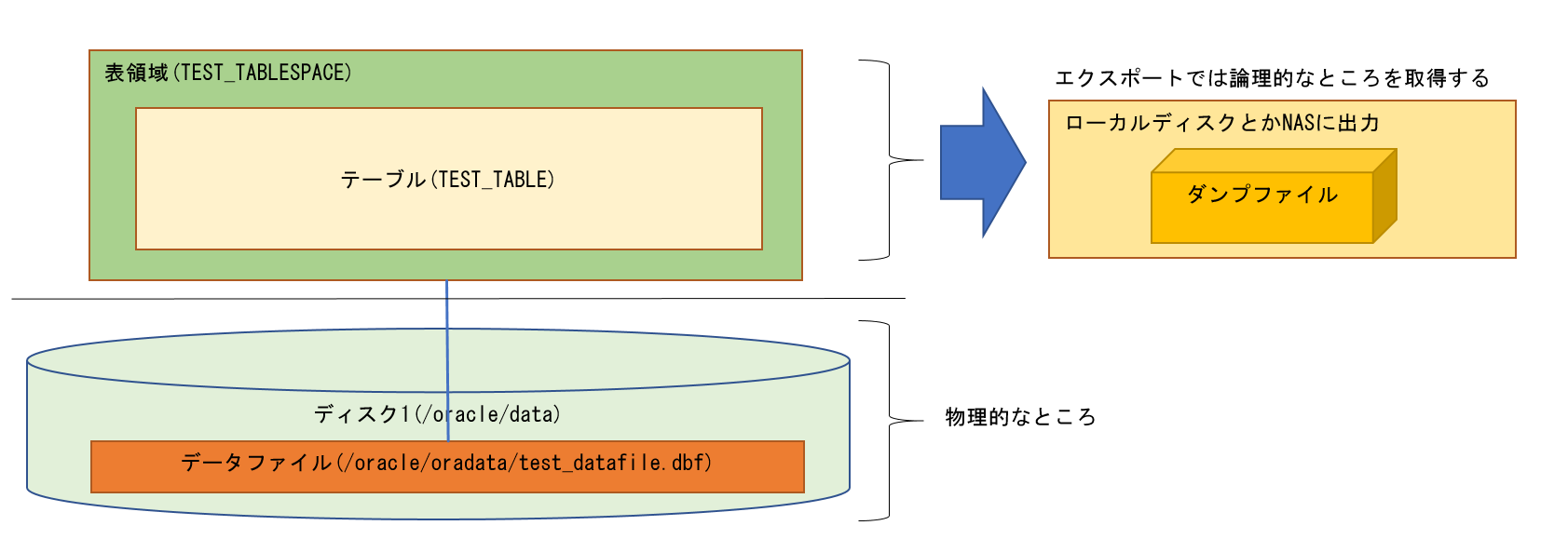
前回のコラムで登場した図で説明すると、「論理的なところ」と言われている部分にあたります。
データポンプなどのユーティリティで手軽に取得されたバックアップが、論理バックアップと言われているのをよく耳にします。
その理由は何でしょうか。
理由を考えるにあたり、まず対極にある物理バックアップが何なのか考えてみました。
物理バックアップというのはメディアバックアップとも言われ、文字通り"ディスクごと"ミラーリング機能などを使ってまるっと、遠隔地のディスクにバックアップするやり方です。
ディスクを別のディスクに物理的にコピーしているので、まさに物理バックアップです。
論理的な部分も物理的な部分も全てコミコミでバックアップしています。
これと比較して、データポンプは物理的な部分、例えばディスクの設定やASMのディスクグループの定義までは取得できません。
なのでダンプファイルを使えば全てを戻せるかというと、そう言うことは出来ません。
物理的な部分(ディスクやASMディスクグループの作成など)を用意して、それからダンプファイルで戻すという手順になります。
データポンプが論理バックアップと呼ばれている理由は、物理的な部分に乗っかっている論理的な部分だけを取得するからそう呼ばれているのだと思います。
こう書くと、物理バックアップに比べて、論理バックアップの方が劣ってるように聞こえますが、そんなことはありません。
物理バックアップから戻す場合、特定のテーブルだけを戻すという、きめ細かいことは出来ません。
データポンプであれば、テーブル一つからバックアップし戻すことが出来ます。
その理由は何でしょうか。
理由を考えるにあたり、まず対極にある物理バックアップが何なのか考えてみました。
物理バックアップというのはメディアバックアップとも言われ、文字通り"ディスクごと"ミラーリング機能などを使ってまるっと、遠隔地のディスクにバックアップするやり方です。
ディスクを別のディスクに物理的にコピーしているので、まさに物理バックアップです。
論理的な部分も物理的な部分も全てコミコミでバックアップしています。
これと比較して、データポンプは物理的な部分、例えばディスクの設定やASMのディスクグループの定義までは取得できません。
なのでダンプファイルを使えば全てを戻せるかというと、そう言うことは出来ません。
物理的な部分(ディスクやASMディスクグループの作成など)を用意して、それからダンプファイルで戻すという手順になります。
データポンプが論理バックアップと呼ばれている理由は、物理的な部分に乗っかっている論理的な部分だけを取得するからそう呼ばれているのだと思います。
こう書くと、物理バックアップに比べて、論理バックアップの方が劣ってるように聞こえますが、そんなことはありません。
物理バックアップから戻す場合、特定のテーブルだけを戻すという、きめ細かいことは出来ません。
データポンプであれば、テーブル一つからバックアップし戻すことが出来ます。
■論理的なバックアップとしての具体的な使い道
私の場合、以下のような使い方をしています。
・データパッチ作業前のバックアップ
本番環境にてデータパッチ作業を行う前に、パッチ対象のテーブルの作業前バックアップを取る際に使用しています。
データパッチの結果が思わしくない場合、取得したダンプファイルから対象テーブルだけを戻すことが出来ます。
もちろん、そういったことが無いように開発環境で十分な検証を行うのが必須なのですが、何かあった時の奥の手として取ってます。
・データパッチ作業前のバックアップ
本番環境にてデータパッチ作業を行う前に、パッチ対象のテーブルの作業前バックアップを取る際に使用しています。
データパッチの結果が思わしくない場合、取得したダンプファイルから対象テーブルだけを戻すことが出来ます。
もちろん、そういったことが無いように開発環境で十分な検証を行うのが必須なのですが、何かあった時の奥の手として取ってます。
・開発環境の構築用
他の開発環境のデータを、別の開発環境に移動したい時に使用します。
他の開発環境のデータを、別の開発環境に移動したい時に使用します。
・ORACLEのバージョンアップを伴うデータ移行
バージョン的に下位のORACLEから上位のORACLEへのデータ移行に使用しています。
実際には、10gのデータベースから11gのデータベースへデータポンプを使って、データ移行したことがあります。
サーバリプレースを伴うORACLEバージョンアップを行う場合は、この方法をまず検討してみて下さい。
バージョン的に下位のORACLEから上位のORACLEへのデータ移行に使用しています。
実際には、10gのデータベースから11gのデータベースへデータポンプを使って、データ移行したことがあります。
サーバリプレースを伴うORACLEバージョンアップを行う場合は、この方法をまず検討してみて下さい。
■実際の運用でも立派なバックアップとして使われています
よく論理バックアップは障害直前まで戻せない、取得時点までの状態にしか戻せないからバックアップとしては使い物にならない、などと言われていますが、それはアーカイブログモードの物理バックアップ(※1)と比べて出来ないからそう言われてしまうだけで、データポンプだけで見たら優れたツールだと思います。
そもそも先程紹介した使い道から考えると、日次のバックアップを目的としたツールでは無いというのが分かります。
従って、物理バックアップと同じ土俵で比較して劣っていると言うのは間違えていると思います。
そもそも先程紹介した使い道から考えると、日次のバックアップを目的としたツールでは無いというのが分かります。
従って、物理バックアップと同じ土俵で比較して劣っていると言うのは間違えていると思います。
と、ここまでデータポンプによる論理バックアップは日次バックアップを目的としていないと語ってきましたが、実際は日次バックアップが論理バックアップ、つまりダンプファイルの現場もありました。
その場合、ORACLEのデータベースが格納されたディスクとダンプファイルが格納されたディスクは別々でした。
サーバが破損そしてディスクも破損した場合、新しいサーバとディスクを用意してデータベースを作成した後、業務データをこのダンプファイルから戻すことになります。
そのために、データベースを一から構築する手順とダンプファイルから戻す手順を、バックアップ・リストア手順書として用意していました。
この運用の場合、ダンプファイル取得時点の状態にしか戻りません。
障害直前の状態まで戻せないの?と言う客さんもいましたが、このバックアップ方法で合意してくれたお客さんもいました。
ですが、合意したお客さんも理想を言えば、データベースをアーカイブログモードで運用し物理バックアップを遠隔地に持って置きたいと思っているはずです。
その場合、ORACLEのデータベースが格納されたディスクとダンプファイルが格納されたディスクは別々でした。
サーバが破損そしてディスクも破損した場合、新しいサーバとディスクを用意してデータベースを作成した後、業務データをこのダンプファイルから戻すことになります。
そのために、データベースを一から構築する手順とダンプファイルから戻す手順を、バックアップ・リストア手順書として用意していました。
この運用の場合、ダンプファイル取得時点の状態にしか戻りません。
障害直前の状態まで戻せないの?と言う客さんもいましたが、このバックアップ方法で合意してくれたお客さんもいました。
ですが、合意したお客さんも理想を言えば、データベースをアーカイブログモードで運用し物理バックアップを遠隔地に持って置きたいと思っているはずです。
■色々なことを考慮して、あえて論理バックアップを選ぶ
皆、出来れば障害直前の状態にまで戻したいはずです。
しかし、障害直前の状態まで戻せるアーカイブログモードと物理バックアップの運用は、予算が沢山必要です。
アーカイブログを格納して置くディスク、遠隔地にディスクをコピーする仕組み、ちゃんと障害直前まで戻るかといった確認など、やる事そして準備するものが多く、コストが高いです。
それと比較すると、ダンプファイルの論理バックアップは管理も楽だし、やる事も準備も格段に少なくなるためコストが低いです。
論理バックアップを選んだお客さんは、バックアップに予算と時間を割けなかったので、その妥協案としてダンプファイルによる運用に落ち着いたということです。
しかし、障害直前の状態まで戻せるアーカイブログモードと物理バックアップの運用は、予算が沢山必要です。
アーカイブログを格納して置くディスク、遠隔地にディスクをコピーする仕組み、ちゃんと障害直前まで戻るかといった確認など、やる事そして準備するものが多く、コストが高いです。
それと比較すると、ダンプファイルの論理バックアップは管理も楽だし、やる事も準備も格段に少なくなるためコストが低いです。
論理バックアップを選んだお客さんは、バックアップに予算と時間を割けなかったので、その妥協案としてダンプファイルによる運用に落ち着いたということです。
理想を実現したい。でもお金が掛かる。そこから、その理想がお客さんにとって本当に必要かは考える必要があります。
本当に障害直前まで戻す必要があるのか、それともバックアップ取得時点までで問題無いのかは、よく話し合って検討すべきです。
分析系システムのように、日中にオンラインでデータの変化が無いようなシステムなら、論理バックアップとバッチの再実行で障害直前まで戻すと言うリカバリ方法にすれば良いと思います。
基幹系システムのように、日中にオンラインでデータが変わるようなシステムの場合は、そのデータ量によると思います。
数百件しかオンライン登録されないようなシステムなら、手入力でカバー出来るかもしれませんが、それが数百万件なら、アーカイブログモードによる物理バックアップを提案したほうがいいかもしれません。
闇雲に高価で理想的な提案するよりも、お客さんのシステムで扱うデータの規模と、日中のデータ変化量を考慮したうえで、バックアップ方法を提案していきたいものです。
本当に障害直前まで戻す必要があるのか、それともバックアップ取得時点までで問題無いのかは、よく話し合って検討すべきです。
分析系システムのように、日中にオンラインでデータの変化が無いようなシステムなら、論理バックアップとバッチの再実行で障害直前まで戻すと言うリカバリ方法にすれば良いと思います。
基幹系システムのように、日中にオンラインでデータが変わるようなシステムの場合は、そのデータ量によると思います。
数百件しかオンライン登録されないようなシステムなら、手入力でカバー出来るかもしれませんが、それが数百万件なら、アーカイブログモードによる物理バックアップを提案したほうがいいかもしれません。
闇雲に高価で理想的な提案するよりも、お客さんのシステムで扱うデータの規模と、日中のデータ変化量を考慮したうえで、バックアップ方法を提案していきたいものです。
-------------------------------------------------------------------------
※1:物理バックアップを取得していたとしても、アーカイブログモードでかつアーカイブログをきちんと管理、運用していなければ、障害直前まで戻せません。
2017年8月17日木曜日
「AIが同僚」を読んで、人間とAIの違いを考える
論文ぽい文章が読みにくかったというか、予備知識が無いと理解できない部分はありました。
前半は、抽象的な表現が多かったのも、ちょっと理解するのに苦労しました。
形容詞が多いから具体的に言いたいことを理解するのに何回も読んでしまいました。
イノベーションとかシンギュラリティとか、そういう単語は分かるんだけどいまいちピンとこない。
後半の、各企業ごとの実績と成果や取り組みを読んで、AIが世の中でどういう風に使われてるのか理解できました。
AIは人の仕事を奪うことは誤解なんだよということを、本書では伝えたいという理由で書かれたとあとがきにあります。
その通りで、本文中でもAIが奪う仕事もあるけど、そうなることで人は新しい仕事を見つけることが出来る。
そして、本当に人が必要な仕事に、その分力を注ぐことが出来るので社会全体が良くなるんだよ、と言うことも理解できました。
本書をよく読んでみると、AIはビッグデータを解析してその中から最適な答えを見つけ出すのが得意と言う感じです。
だから、少ない情報でも判断したり、場の空気を読んで対応を決定する人間の知能とは異なると思いました。
あくまでも、AIは判断をするうえで、大量のデータありきで、それが無いと正確な判断が出来ないんだと思います。
そう言う点では、従来のコンピュータとあまり変わらないという気もします。
ただ、昔にそれが出来なかったのは、大容量の記憶装置も高性能のCPUも無かったからで、現代だから実現出来て来たのだと思います。
そう言う意味では、今後もコンピュータの性能は良くなっていくだろうから、AIを限りなく本当の知能に近い状態に今後持っていくことは可能ですね。
無限にあるパターンの表情データをたくさん読み込ませれば、かなりの精度で笑顔とか怒った顔を判別できるようになるのでしょう。
でも、それは中のプログラムが大量のデータを処理しているだけなのであって、AIがその笑顔の本当の意味は分からないし、どうして怒った顔をしてるのかはきっと分からない。
感情とかそういうものは、データ化出来ないからだと思いました。
だけど、大量のデータとの照合で笑顔が何なのか分かるし、怒った顔も分かる。
AIには、表情の意味なんて分からないし、そこが人間との大きな差だと思います。
だから、AIがいくら発展しても人間は何らかの仕事があるはずだと思いました。
それは、本書でも書かれている東ロボくんの例でもよく分かりました。
東ロボくんは、平均偏差値以上の点数を叩き出すようになりました。
が、結局、東ロボくんは人間だったら簡単に分かる英語の問題を間違えてしまいました。
それは、文章の意味が分からなかったからでした。
それを読んで、本当の知能は言葉の意味や自分の置かれた状況から答えを導き出すものだと理解しました。
|
2017年8月13日日曜日
【ORACLEのお勉強#01】テーブル、表領域、データファイル、ディスクの関係
■ORACLEの論理と物理
ORACLEで言うところの論理と物理って何だろうと考えてみました。※1
10年以上、ORACLEと付き合って来た私は、以下の図の通りという認識です。
物凄く簡略化していますが、こういった感じです。
10年以上、ORACLEと付き合って来た私は、以下の図の通りという認識です。
物凄く簡略化していますが、こういった感じです。

・論理的なところ
・テーブル
・表領域
(他にもマテリアライズドビューやシーケンスもありますが、省略しています。)
・テーブル
・表領域
(他にもマテリアライズドビューやシーケンスもありますが、省略しています。)
・物理的なところ
・データファイル
・ディスク
(他にもREDOログや制御ファイルもありますが、省略しています。)
・データファイル
・ディスク
(他にもREDOログや制御ファイルもありますが、省略しています。)
スクリプトで上記の図を表現すると、以下の通りです。
・テーブル
CREATE TABLE TEST_TABLE
(
TEST_COL1 CHAR(3),
TEST_COL2 CHAR(3),
TEST_COL3 VARCHAR2(10)
) TABLESPACE TEST_TABLESPACE;・表領域
CREATE TABLESPACE TEST_TABLESPACE
DATAFILE '/oracle/data/test_datafile.dbf' SIZE 100M;
■テーブルが出来るまで
物に例えるとかえって分かりにくくなると思ったし、ORACLE用語のままのほうがスムーズに説明できるので、多少、専門用語が出てきますが頑張ってください。
まずは、どういう順番でディスクからテーブルまでが構築されるか説明します。
ORACLEはインストール済み、業務データが無いデータベースが作成済みとします。
(SYSTEM表領域にあるデータだけを持った、実質空のデータベースです)
まずは、どういう順番でディスクからテーブルまでが構築されるか説明します。
ORACLEはインストール済み、業務データが無いデータベースが作成済みとします。
(SYSTEM表領域にあるデータだけを持った、実質空のデータベースです)
1.データ領域用のディスクを用意します。
2.そのディスクに表領域を作成します。
どのディスクの、どこのディレクトリにデータファイルを配置するかスクリプトにて定義します。
3.表領域指定してテーブルを作成します。
2.そのディスクに表領域を作成します。
どのディスクの、どこのディレクトリにデータファイルを配置するかスクリプトにて定義します。
3.表領域指定してテーブルを作成します。
テーブルを作るときに意識するのは表領域とテーブルサイズだけで、どこのディスクのどのデータファイルに作られるかと言った物理的な事は意識する必要ありません。
こう言った感じで物理から始まって論理に向かって行くわけです。
DBAが意識するのは1と2で、開発者が意識するのは3です。
つまり、開発者はどのテーブルにどんなデータが入っているかだけを気にし、DBAは表領域、ディスク、データファイルのサイズと使用量を気にしています。
こう言った感じで物理から始まって論理に向かって行くわけです。
DBAが意識するのは1と2で、開発者が意識するのは3です。
つまり、開発者はどのテーブルにどんなデータが入っているかだけを気にし、DBAは表領域、ディスク、データファイルのサイズと使用量を気にしています。
では、データベース設計の時はどうなのかと言うと実は、構築時の逆、論理的なところからスタートします。
1.全テーブルのサイズを計算します。
2.各テーブルをどの表領域に格納するかを決めます。
3.表領域のサイズを決めます。
サイズは表領域に配置する各テーブルのサイズを合計したものになります。
4.各表領域をどのディスクに配置するか決めます。
ASMの場合は、どのASMディスクグループに配置するかを決めることになります。
5.ディスクのサイズを決定します。
各ディスクは、3で計算した表領域を配置できるサイズを用意します。
余裕を持たせて大きめのサイズにすることが多いです。
2.各テーブルをどの表領域に格納するかを決めます。
3.表領域のサイズを決めます。
サイズは表領域に配置する各テーブルのサイズを合計したものになります。
4.各表領域をどのディスクに配置するか決めます。
ASMの場合は、どのASMディスクグループに配置するかを決めることになります。
5.ディスクのサイズを決定します。
各ディスクは、3で計算した表領域を配置できるサイズを用意します。
余裕を持たせて大きめのサイズにすることが多いです。
最初は業務から情報を引き出すところからです。
業務から訊き出した各テーブルのカラム数、型、桁数そして、格納されるであろう最大件数が、最後に用意されるディスクのサイズに影響します。
ソフトウエア開発のV字モデルのような形がここでも出て来ていて、これに気付いたとき既視感を覚えたものです。
業務から訊き出した各テーブルのカラム数、型、桁数そして、格納されるであろう最大件数が、最後に用意されるディスクのサイズに影響します。
ソフトウエア開発のV字モデルのような形がここでも出て来ていて、これに気付いたとき既視感を覚えたものです。
■実際の運用
本番運用が始まると、データベースは容易に変更できなくなります。
データベースの変更は、業務サービスの停止を余儀なくされる場合が多いからです。
それでも変更がどうしても必要な場合は、お客さんと調整して土日などにシステムを停止して変更を行います。
変更が多い順に並べると、テーブル、表領域、データファイル、ディスクとなります。
健全な設計を行ってきたデータベースなら、変更対象のほとんどがテーブルであり、表領域やデータファイルに変更は余り無いと言っても過言ではありません。
逆に設計時のサイジングが適当だった場合、ディスクの追加や表領域の作り直しと行った大規模で時間の掛かる作業を、本番環境で行う羽目になります。
それだけは避けたいので、最初のテーブルサイズ計算から慎重に行うのが大事です。
データベースの変更は、業務サービスの停止を余儀なくされる場合が多いからです。
それでも変更がどうしても必要な場合は、お客さんと調整して土日などにシステムを停止して変更を行います。
変更が多い順に並べると、テーブル、表領域、データファイル、ディスクとなります。
健全な設計を行ってきたデータベースなら、変更対象のほとんどがテーブルであり、表領域やデータファイルに変更は余り無いと言っても過言ではありません。
逆に設計時のサイジングが適当だった場合、ディスクの追加や表領域の作り直しと行った大規模で時間の掛かる作業を、本番環境で行う羽目になります。
それだけは避けたいので、最初のテーブルサイズ計算から慎重に行うのが大事です。
■まとめ
こうして物理層と論理層が分かれているため、開発する側と管理する側で、お互いを意識しなくていいようになっている訳です。
表領域を別のディスクに再配置したりサイズを大きくしても、プログラムを変える必要は無いですし、プログラムを作るうえでテーブルがどこのディスクにあるかを考える必要はありません。
ディスクというハードに寄れるば寄る程、物理的な立場にいると言えるし、遠ざかる程、論理的な立場にいると言えます。
どちらが優れているとかと言うわけでは無くて、役割の違いだけだと思ってます。
ただ、物理に近い部分を扱うようになるとOSやハードの知識が必要になるのは確かだし、論理に近くなればテーブルのつながりや業務の知識が必要になって来ると思います。
どちらの立場にいても、時間に余裕があればお互いのことを少し知っておくと開発が円滑に進むかもしれません。
表領域を別のディスクに再配置したりサイズを大きくしても、プログラムを変える必要は無いですし、プログラムを作るうえでテーブルがどこのディスクにあるかを考える必要はありません。
ディスクというハードに寄れるば寄る程、物理的な立場にいると言えるし、遠ざかる程、論理的な立場にいると言えます。
どちらが優れているとかと言うわけでは無くて、役割の違いだけだと思ってます。
ただ、物理に近い部分を扱うようになるとOSやハードの知識が必要になるのは確かだし、論理に近くなればテーブルのつながりや業務の知識が必要になって来ると思います。
どちらの立場にいても、時間に余裕があればお互いのことを少し知っておくと開発が円滑に進むかもしれません。
-------------------------------------------------------------------------
※1:考えたのはデータ領域についてのみです。
REDOログ、制御ファイル、UNDO、一時表領域は割愛しました。
ORACLEのソフトウエア自体がインストールされている領域についても考慮していません。
REDOログ、制御ファイル、UNDO、一時表領域は割愛しました。
ORACLEのソフトウエア自体がインストールされている領域についても考慮していません。
登録:
コメント (Atom)