
ORACLEデータベースのバックアップと聞いて、多くの人が、まず思い浮かぶのがexp、impコマンドだと思います。
10gからは、その高機能版であるデータポンプが登場しました。
10gからは、その高機能版であるデータポンプが登場しました。
■普通のエクスポート、インポートとデータポンプの違い
・普通のエクスポート、インポート(exp、imp)
・10gまでサポートされている。11gからはサポートされていない。
・コマンド(例)
exp xxx/xxx file=a.dmp log=a.log tables=a
imp xxx/xxx file=a.dmp log=a_imp.log tables=a
・データポンプのようにディレクトリオブジェクトを用意したりといった下準備が要らない
・10gまでサポートされている。11gからはサポートされていない。
・コマンド(例)
exp xxx/xxx file=a.dmp log=a.log tables=a
imp xxx/xxx file=a.dmp log=a_imp.log tables=a
・データポンプのようにディレクトリオブジェクトを用意したりといった下準備が要らない
・データポンプ
・使うにあたり準備がいる
ディレクトリオブジェクトが必要
初期化パラメータSTREAMS_POOL_SIZEの設定が必要
・コマンド(例)
expdp xxx/xxx dumpfile=a.dmp logfile=a.log tables=a
impdp xxx/xxx dumpfile=a.dmp logfile=a_imp.log tables=a
・数千万クラスのテーブルだと、普通の普通のエクスポート、インポートよりデータ取得が速い
・使うにあたり準備がいる
ディレクトリオブジェクトが必要
初期化パラメータSTREAMS_POOL_SIZEの設定が必要
・コマンド(例)
expdp xxx/xxx dumpfile=a.dmp logfile=a.log tables=a
impdp xxx/xxx dumpfile=a.dmp logfile=a_imp.log tables=a
・数千万クラスのテーブルだと、普通の普通のエクスポート、インポートよりデータ取得が速い
普通のエクスポート、インポートよりもデータポンプの方が内部動作が複雑だし、設定をミスっているとORA-エラーが出て対処が必要になる場合もあります。
そのため、敷居が高い印象です。
私も使う前はそうでした。
10gの頃のデータポンプはバグが多かった......ですが、11gからは安定した動きになっています。
実際、普通のエクスポート、インポートとデータポンプの性能を比較すると、数百万件の単純な型しか持たないテーブルだと時間差を感じないのですが、LOBや構造体など複雑な型を持つテーブルを数千万件単位で取得する時は、データポンプの方が圧倒的に速かったです。
ここからは、データポンプに絞って書いていきます。
そのため、敷居が高い印象です。
私も使う前はそうでした。
10gの頃のデータポンプはバグが多かった......ですが、11gからは安定した動きになっています。
実際、普通のエクスポート、インポートとデータポンプの性能を比較すると、数百万件の単純な型しか持たないテーブルだと時間差を感じないのですが、LOBや構造体など複雑な型を持つテーブルを数千万件単位で取得する時は、データポンプの方が圧倒的に速かったです。
ここからは、データポンプに絞って書いていきます。
■よく論理バックアップ、物理バックアップと言われていますが......
データポンプで取得できるORACLEのデータは何でしょうか?
私は以下の図の範囲だと考えています。
私は以下の図の範囲だと考えています。
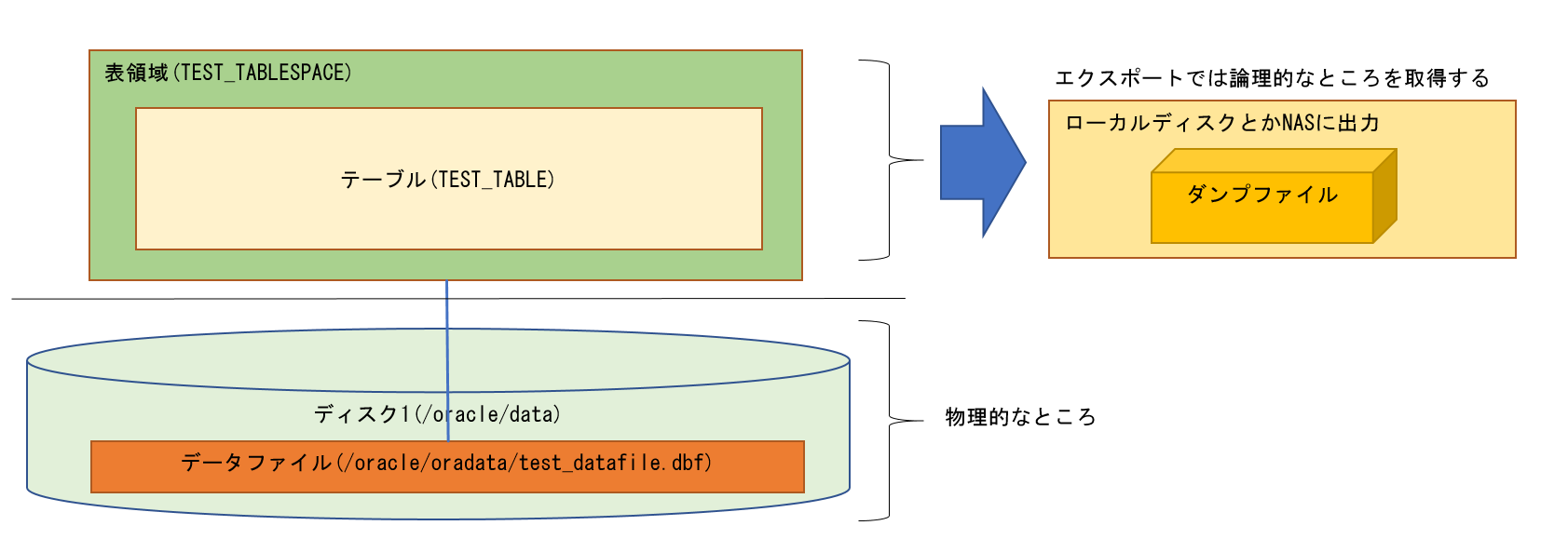
前回のコラムで登場した図で説明すると、「論理的なところ」と言われている部分にあたります。
データポンプなどのユーティリティで手軽に取得されたバックアップが、論理バックアップと言われているのをよく耳にします。
その理由は何でしょうか。
理由を考えるにあたり、まず対極にある物理バックアップが何なのか考えてみました。
物理バックアップというのはメディアバックアップとも言われ、文字通り"ディスクごと"ミラーリング機能などを使ってまるっと、遠隔地のディスクにバックアップするやり方です。
ディスクを別のディスクに物理的にコピーしているので、まさに物理バックアップです。
論理的な部分も物理的な部分も全てコミコミでバックアップしています。
これと比較して、データポンプは物理的な部分、例えばディスクの設定やASMのディスクグループの定義までは取得できません。
なのでダンプファイルを使えば全てを戻せるかというと、そう言うことは出来ません。
物理的な部分(ディスクやASMディスクグループの作成など)を用意して、それからダンプファイルで戻すという手順になります。
データポンプが論理バックアップと呼ばれている理由は、物理的な部分に乗っかっている論理的な部分だけを取得するからそう呼ばれているのだと思います。
こう書くと、物理バックアップに比べて、論理バックアップの方が劣ってるように聞こえますが、そんなことはありません。
物理バックアップから戻す場合、特定のテーブルだけを戻すという、きめ細かいことは出来ません。
データポンプであれば、テーブル一つからバックアップし戻すことが出来ます。
その理由は何でしょうか。
理由を考えるにあたり、まず対極にある物理バックアップが何なのか考えてみました。
物理バックアップというのはメディアバックアップとも言われ、文字通り"ディスクごと"ミラーリング機能などを使ってまるっと、遠隔地のディスクにバックアップするやり方です。
ディスクを別のディスクに物理的にコピーしているので、まさに物理バックアップです。
論理的な部分も物理的な部分も全てコミコミでバックアップしています。
これと比較して、データポンプは物理的な部分、例えばディスクの設定やASMのディスクグループの定義までは取得できません。
なのでダンプファイルを使えば全てを戻せるかというと、そう言うことは出来ません。
物理的な部分(ディスクやASMディスクグループの作成など)を用意して、それからダンプファイルで戻すという手順になります。
データポンプが論理バックアップと呼ばれている理由は、物理的な部分に乗っかっている論理的な部分だけを取得するからそう呼ばれているのだと思います。
こう書くと、物理バックアップに比べて、論理バックアップの方が劣ってるように聞こえますが、そんなことはありません。
物理バックアップから戻す場合、特定のテーブルだけを戻すという、きめ細かいことは出来ません。
データポンプであれば、テーブル一つからバックアップし戻すことが出来ます。
■論理的なバックアップとしての具体的な使い道
私の場合、以下のような使い方をしています。
・データパッチ作業前のバックアップ
本番環境にてデータパッチ作業を行う前に、パッチ対象のテーブルの作業前バックアップを取る際に使用しています。
データパッチの結果が思わしくない場合、取得したダンプファイルから対象テーブルだけを戻すことが出来ます。
もちろん、そういったことが無いように開発環境で十分な検証を行うのが必須なのですが、何かあった時の奥の手として取ってます。
・データパッチ作業前のバックアップ
本番環境にてデータパッチ作業を行う前に、パッチ対象のテーブルの作業前バックアップを取る際に使用しています。
データパッチの結果が思わしくない場合、取得したダンプファイルから対象テーブルだけを戻すことが出来ます。
もちろん、そういったことが無いように開発環境で十分な検証を行うのが必須なのですが、何かあった時の奥の手として取ってます。
・開発環境の構築用
他の開発環境のデータを、別の開発環境に移動したい時に使用します。
他の開発環境のデータを、別の開発環境に移動したい時に使用します。
・ORACLEのバージョンアップを伴うデータ移行
バージョン的に下位のORACLEから上位のORACLEへのデータ移行に使用しています。
実際には、10gのデータベースから11gのデータベースへデータポンプを使って、データ移行したことがあります。
サーバリプレースを伴うORACLEバージョンアップを行う場合は、この方法をまず検討してみて下さい。
バージョン的に下位のORACLEから上位のORACLEへのデータ移行に使用しています。
実際には、10gのデータベースから11gのデータベースへデータポンプを使って、データ移行したことがあります。
サーバリプレースを伴うORACLEバージョンアップを行う場合は、この方法をまず検討してみて下さい。
■実際の運用でも立派なバックアップとして使われています
よく論理バックアップは障害直前まで戻せない、取得時点までの状態にしか戻せないからバックアップとしては使い物にならない、などと言われていますが、それはアーカイブログモードの物理バックアップ(※1)と比べて出来ないからそう言われてしまうだけで、データポンプだけで見たら優れたツールだと思います。
そもそも先程紹介した使い道から考えると、日次のバックアップを目的としたツールでは無いというのが分かります。
従って、物理バックアップと同じ土俵で比較して劣っていると言うのは間違えていると思います。
そもそも先程紹介した使い道から考えると、日次のバックアップを目的としたツールでは無いというのが分かります。
従って、物理バックアップと同じ土俵で比較して劣っていると言うのは間違えていると思います。
と、ここまでデータポンプによる論理バックアップは日次バックアップを目的としていないと語ってきましたが、実際は日次バックアップが論理バックアップ、つまりダンプファイルの現場もありました。
その場合、ORACLEのデータベースが格納されたディスクとダンプファイルが格納されたディスクは別々でした。
サーバが破損そしてディスクも破損した場合、新しいサーバとディスクを用意してデータベースを作成した後、業務データをこのダンプファイルから戻すことになります。
そのために、データベースを一から構築する手順とダンプファイルから戻す手順を、バックアップ・リストア手順書として用意していました。
この運用の場合、ダンプファイル取得時点の状態にしか戻りません。
障害直前の状態まで戻せないの?と言う客さんもいましたが、このバックアップ方法で合意してくれたお客さんもいました。
ですが、合意したお客さんも理想を言えば、データベースをアーカイブログモードで運用し物理バックアップを遠隔地に持って置きたいと思っているはずです。
その場合、ORACLEのデータベースが格納されたディスクとダンプファイルが格納されたディスクは別々でした。
サーバが破損そしてディスクも破損した場合、新しいサーバとディスクを用意してデータベースを作成した後、業務データをこのダンプファイルから戻すことになります。
そのために、データベースを一から構築する手順とダンプファイルから戻す手順を、バックアップ・リストア手順書として用意していました。
この運用の場合、ダンプファイル取得時点の状態にしか戻りません。
障害直前の状態まで戻せないの?と言う客さんもいましたが、このバックアップ方法で合意してくれたお客さんもいました。
ですが、合意したお客さんも理想を言えば、データベースをアーカイブログモードで運用し物理バックアップを遠隔地に持って置きたいと思っているはずです。
■色々なことを考慮して、あえて論理バックアップを選ぶ
皆、出来れば障害直前の状態にまで戻したいはずです。
しかし、障害直前の状態まで戻せるアーカイブログモードと物理バックアップの運用は、予算が沢山必要です。
アーカイブログを格納して置くディスク、遠隔地にディスクをコピーする仕組み、ちゃんと障害直前まで戻るかといった確認など、やる事そして準備するものが多く、コストが高いです。
それと比較すると、ダンプファイルの論理バックアップは管理も楽だし、やる事も準備も格段に少なくなるためコストが低いです。
論理バックアップを選んだお客さんは、バックアップに予算と時間を割けなかったので、その妥協案としてダンプファイルによる運用に落ち着いたということです。
しかし、障害直前の状態まで戻せるアーカイブログモードと物理バックアップの運用は、予算が沢山必要です。
アーカイブログを格納して置くディスク、遠隔地にディスクをコピーする仕組み、ちゃんと障害直前まで戻るかといった確認など、やる事そして準備するものが多く、コストが高いです。
それと比較すると、ダンプファイルの論理バックアップは管理も楽だし、やる事も準備も格段に少なくなるためコストが低いです。
論理バックアップを選んだお客さんは、バックアップに予算と時間を割けなかったので、その妥協案としてダンプファイルによる運用に落ち着いたということです。
理想を実現したい。でもお金が掛かる。そこから、その理想がお客さんにとって本当に必要かは考える必要があります。
本当に障害直前まで戻す必要があるのか、それともバックアップ取得時点までで問題無いのかは、よく話し合って検討すべきです。
分析系システムのように、日中にオンラインでデータの変化が無いようなシステムなら、論理バックアップとバッチの再実行で障害直前まで戻すと言うリカバリ方法にすれば良いと思います。
基幹系システムのように、日中にオンラインでデータが変わるようなシステムの場合は、そのデータ量によると思います。
数百件しかオンライン登録されないようなシステムなら、手入力でカバー出来るかもしれませんが、それが数百万件なら、アーカイブログモードによる物理バックアップを提案したほうがいいかもしれません。
闇雲に高価で理想的な提案するよりも、お客さんのシステムで扱うデータの規模と、日中のデータ変化量を考慮したうえで、バックアップ方法を提案していきたいものです。
本当に障害直前まで戻す必要があるのか、それともバックアップ取得時点までで問題無いのかは、よく話し合って検討すべきです。
分析系システムのように、日中にオンラインでデータの変化が無いようなシステムなら、論理バックアップとバッチの再実行で障害直前まで戻すと言うリカバリ方法にすれば良いと思います。
基幹系システムのように、日中にオンラインでデータが変わるようなシステムの場合は、そのデータ量によると思います。
数百件しかオンライン登録されないようなシステムなら、手入力でカバー出来るかもしれませんが、それが数百万件なら、アーカイブログモードによる物理バックアップを提案したほうがいいかもしれません。
闇雲に高価で理想的な提案するよりも、お客さんのシステムで扱うデータの規模と、日中のデータ変化量を考慮したうえで、バックアップ方法を提案していきたいものです。
-------------------------------------------------------------------------
※1:物理バックアップを取得していたとしても、アーカイブログモードでかつアーカイブログをきちんと管理、運用していなければ、障害直前まで戻せません。
